 De Bruijn Sequence and Universal Cycle Constructions
De Bruijn Sequence and Universal Cycle Constructions
| Min/Random/Max Discrepancy | Output | ||||||||
|
As articulated in [Gol17], binary DB sequences
- are balanced as they contain the same number of $0$s and $1$s;
- satisfy a run property as there are an equal number of contiguous runs of 0s and 1s of the same length in the sequence;
- satisfy a span-$n$ property as they contain every distinct length $n$ binary string as a substring.
Discrepancy
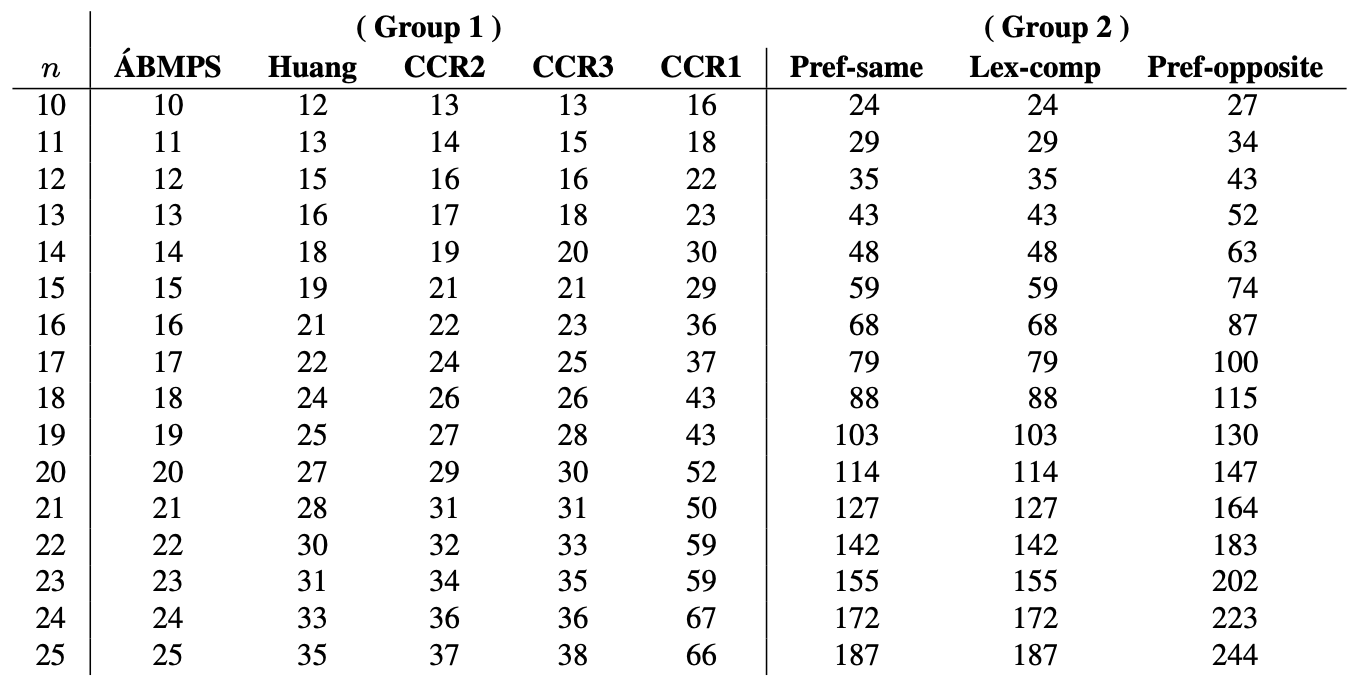
Since every DB sequence contains the string $0^n$, the minimum possible discrepancy of a DB sequence is $n$. The DB sequences with the smallest discrepancy are based on the complementing cycling register (CCR). The two CCR concatenation constructions in [GS18], which correspond to the successor rules CCR2 and CCR3, have a discrepancy less than $2n$. Experimentally, the successor rule by Huang [Hua90] (CCR4) demonstrates a slightly smaller discrepancy. In fact, there exists a construction that attains the minimum possible discrepancy of $n$ over a binary alphabet [ABM+24]; for a non-binary alphabet, they generalizes the CCR to the incrementing cycling register (ICR) for non-binary alphabets, to attain a discrepancy of $n+1$. They conjecture that the minimum discrepancy is $n$ except for $n=2$ and $k=3,4$.
The greedy Prefer-same and Prefer-opposite constructions, along with the lexicographic composition concatenation approach, can all be generated via successor rules based on the PRR. They all appear to have discrepancies of $O(n^2)$. The table below summarizes their discrepancies along with the four successor rules based on the CCR.
The DB sequences with the maximal discrepancy can be obtained by considering weight (density) ranges. By taking a universal cycle $U_1$ for all binary strings with weight from 0 to $\lceil n/2 \rceil -1$ and joining it with a universal cycle $U_2$ for all binary strings with weight from $\lceil n/2 \rceil$ to $n$, the discrepancy of the resulting sequence will be close to the discrepancy of $U_1$, which is ${n-1 \choose \lfloor n/2 \rfloor}$. It is conjectured that the maximal discrepancy for any DB sequence is ${n-1 \choose \lfloor n/2 \rfloor} + \lfloor n/2 \rfloor$, which by Stirling's approximation is $\Theta(\frac{2^n}{\sqrt{n}})$. This is exactly the discrepancy obtained by this construction, which is available for generation and download above [GS22]. The table below shows the discrepancy of this sequence, along with the cool-lex concatenation construction, which is also based on weight ranges (and the PSR/CSR). The table also illustrates the discrepancies for the successor rules PCR1 (Granddaddy), PCR2 (Grandmama), PCR3, and PCR4. The sequences generated by the PCR1 construction are known to have discrepancy $\Theta(\frac{2^n\log n}{n})$ [CH10].
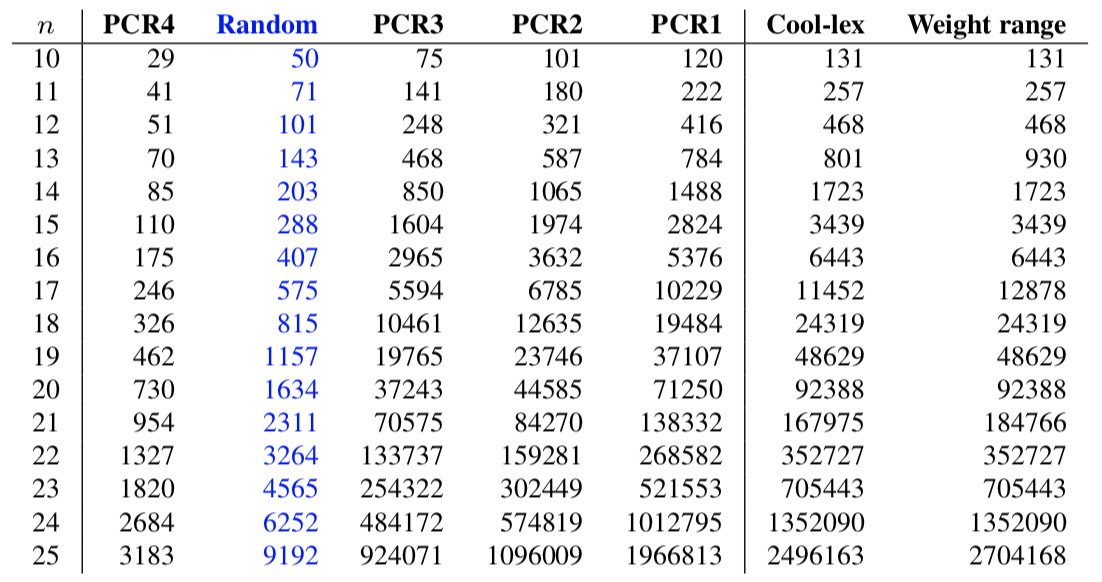
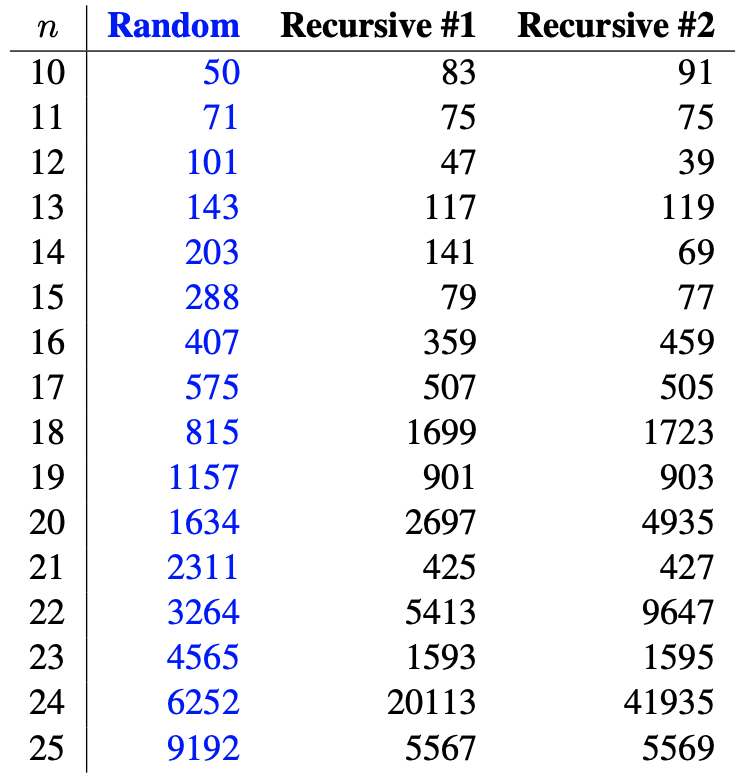
The "Random" column is obtained by taking the average discrepancy of 10000 random sequences of length $2^n$. Such a random sequence is expected to have discrepancy $\Theta(2^{n/2} \sqrt{\log n})$. It remains an interesting problem to define/construct a DB sequence that is provably close to these random values. Experimentally, PCR4 is the successor rule that constructs a DB sequence that is closest to the expected discrepancy of a random sequence. The following table shows the discrepancy of two recursive constructions based on Lempel's lift.
The table below considers the discrepancy over all LFSRs based on primitive polynomials. The minimum, average, and maximum discrepancies are illustrated against our random target. While these sequences demonstrate discrepancy closest to what one expects from a random sequence, the fact that the underlying LFSR can be so easily decoded (as noted above) limits their application.
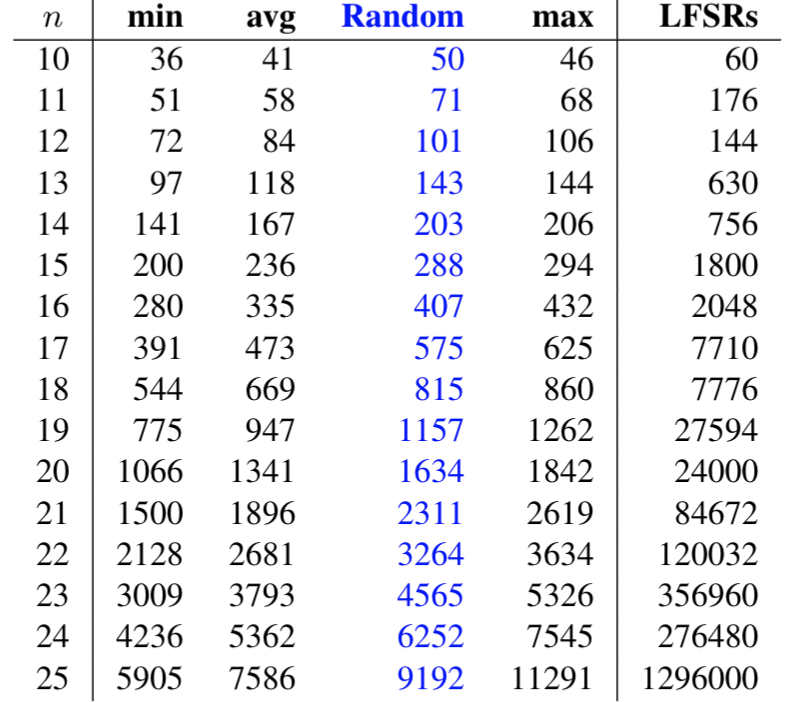
For $12< n \leq 25$, there exists a DB sequence generated by an LFSR (try it above!) that has a discrepancy differing by at most one from the random target. Feedback functions for such LFSRs are given below.

- [ABM+24] N. Álverez, V. Becher, M. Mereb, I. Pajor, C. Soto. De Bruijn sequences with minimum discrepancy . arXiv preprint arXiv:2407.17367, 2024.
- [CH10] J. Cooper and C. Heitsch. The discrepancy of the lex-least de Bruijn sequence. Discrete Math., 310(6-7):1152-1159, 2010.
- [Gol17] S. W. Golomb. Shift Register Sequences (Third Edition). World Scientific, Singapore, 2017.
- [GS18] D. Gabric and J. Sawada. Constructing de Bruijn sequences by concatenating smaller universal cycles. Theoret. Comput. Sci., 743:12-22, 2018.
- [GS22] D. Gabric and J. Sawada. Investigating the discrepancy property of de Bruijn sequences. Discrete Mathematics, 345(4):112780, 2022.
- [Hua90] Y. J. Huang. A new algorithm for the generation of binary de Bruijn sequences. J. Algorithms, 11(1):44-51, 1990.
- [Mas69] J. Massey. Shift-register synthesis and BCH decoding. IEEE Transactions on Information Theory, 15(1):122–127,1969.